Semantic Interoperability
 One often reads about data as the new oil of the 21st century – or maybe not. When British mathematician Clive Humby declared in 2006 that “data is the new oil,” he meant that data, like oil, isn’t useful in its raw state. It needs to be refined, processed and turned into something useful; its value lies in its potential.
One often reads about data as the new oil of the 21st century – or maybe not. When British mathematician Clive Humby declared in 2006 that “data is the new oil,” he meant that data, like oil, isn’t useful in its raw state. It needs to be refined, processed and turned into something useful; its value lies in its potential.
In order to exploit the value of data (i.e., gain insights from data), a number of prerequisites must first be met. First, data must be published by the provider. This process is already quite complex, especially if the goal is to make the data easy to find and use for potential consumers. Second, the data must be findable. While search engines are remarkably capable of solving this task for websites, images or videos, finding data is still an insufficiently solved problem.
Once the data has been found, the next prerequisite for gaining knowledge is the successful integration of the data into a processing system. To do this, the problem of data access must first be solved. While access to Web pages is comparatively trivial and takes place worldwide via the same, standardized operation(s), access to data must be far more diverse. After all, it is not the data descriptions that need to be integrated, but the data itself, which can take any form. Fortunately, the same practices that have made the World Wide Web so successful are increasingly being used for data today. Restricting access to a defined set of standardized data formats and combining them with the access mechanisms of the WWW is a significant step forward.
Once the data is received and loaded into the processing system, it is analyzed and potentially blended with other data to derive insights. Again, data integration is a much more difficult undertaking than consuming simple web pages. While the latter are written in comparatively few and nowadays automatically translatable languages, the “languages” of data are infinite. At the same time, natural languages benefit from centuries of use while adapting slowly, evolved. They thus allow a high degree of intelligibility and consequently communication. Data, on the other hand, cannot look back on a comparable development. Moreover, intelligibility is not necessarily the primary goal here, but other aspects such as storage space or machine processing speed.
In order to make data findable or usable, they must first be described. This raises the fundamental problem of different world views. The potential user is faced with a range of possibilities for how a real world feature might be described, what different viewpoints might offer, how to reconcile different viewpoints to compare or combine these and a plethora of different ways the data is organized, accessed and formatted.
Data Description
Each data provider makes its data available under a particular view of the world. An employee of the urban planning office views a tree differently than a forester or a cultural scientist. The problem of different world views occurs with data and metadata alike. The following example describes a single tree from three perspectives. In all three cases, the tree is exactly the same, the Gerichtslinde in Kriftel, Germany, a silver lime tree first mentioned in 1555, under which court was held.

The data examples differ not only in the attribution, but also in the naming of the object. How can this data now be described so that a third party can find or utilize it, which in turn bases its own world view on the search or utilization?
Conceptual, logical, and physical models
The key here is to break down the model on which the data is based into different levels of abstraction. A distinction is made between conceptual, logical, physical and transactional models. The conceptual model defines the existential properties of the tree; thus those characteristics, which make a specific tree a tree and allow an identifier to be assigned, as well as its relations to other object types. Conceptual models give identity to object types, that is, classes of certain objects in the real world. In our case, these are objects of the type tree.
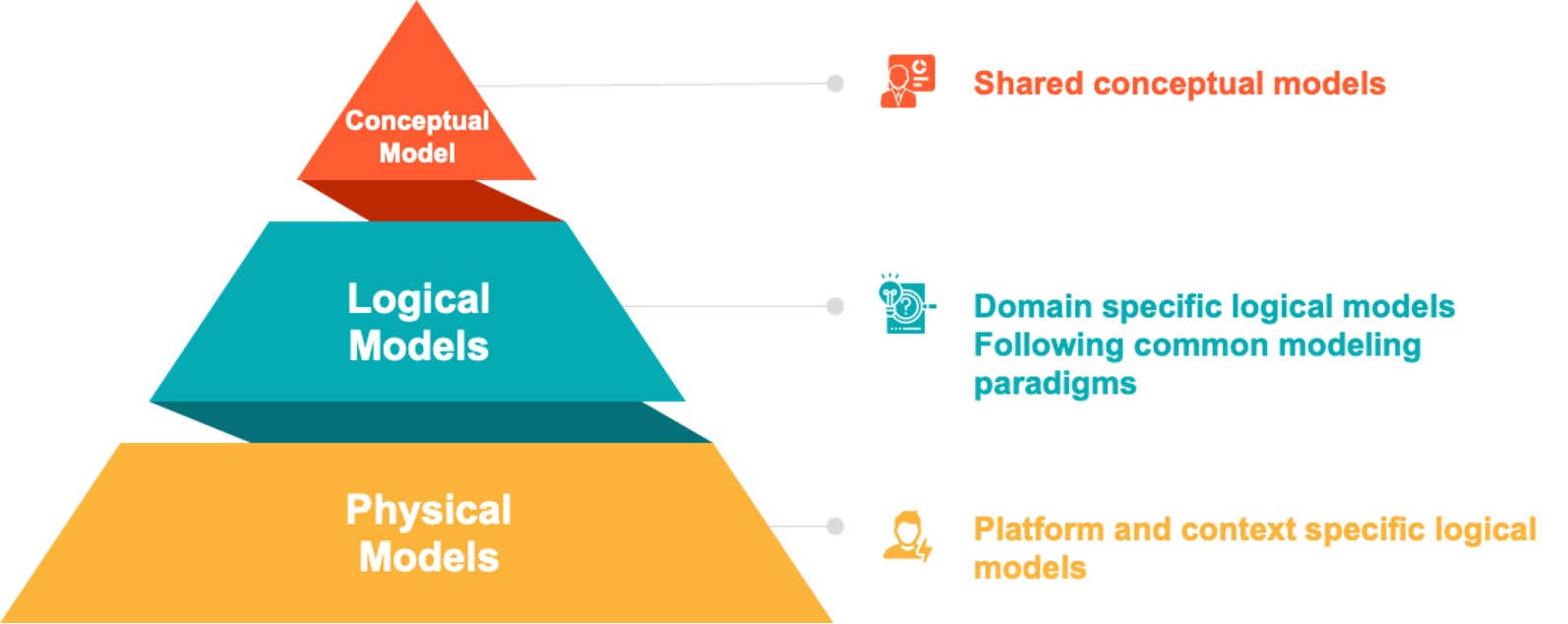 The logical models now provide options to concretize the conceptual object types by means of attributes and attribute value ranges. In everyday life it shows that logical models are defined frequently as partial copies of several already existing models. One speaks here also of implementation profiles, which pick out in each case the necessary model elements and reuse for their purpose. The attribute values or value ranges of these profiles are frequently present in the form of codelists or taxonomies, but may also be expressed as additional related data models for in-depth descriptions – such as the relationships between observation procedures and sensors.
The logical models now provide options to concretize the conceptual object types by means of attributes and attribute value ranges. In everyday life it shows that logical models are defined frequently as partial copies of several already existing models. One speaks here also of implementation profiles, which pick out in each case the necessary model elements and reuse for their purpose. The attribute values or value ranges of these profiles are frequently present in the form of codelists or taxonomies, but may also be expressed as additional related data models for in-depth descriptions – such as the relationships between observation procedures and sensors.
The physical model deals with the implementation of the logical model in a specific technical environment or platform. It describes how to store objects of this type or exchange them over the Internet. Concrete exchange objects often represent only a subset of the logical model or combine elements from several logical models. These objects follow the transaction model. In contrast to data bases the transaction model concentrates on the actually transferred aspects of an object. It deviates thus from the transaction model with data bases, with which a transaction is regarded as a logical unit of work, which is either completely executed or not at all.
Many datasets are created by copying parts of already existing data models. This can lead to confusing situations, as shown below. The attribute “height” appears twice. Without further information it is not obvious that in one case it refers to the total height, while in the second case it refers to the trunk height.

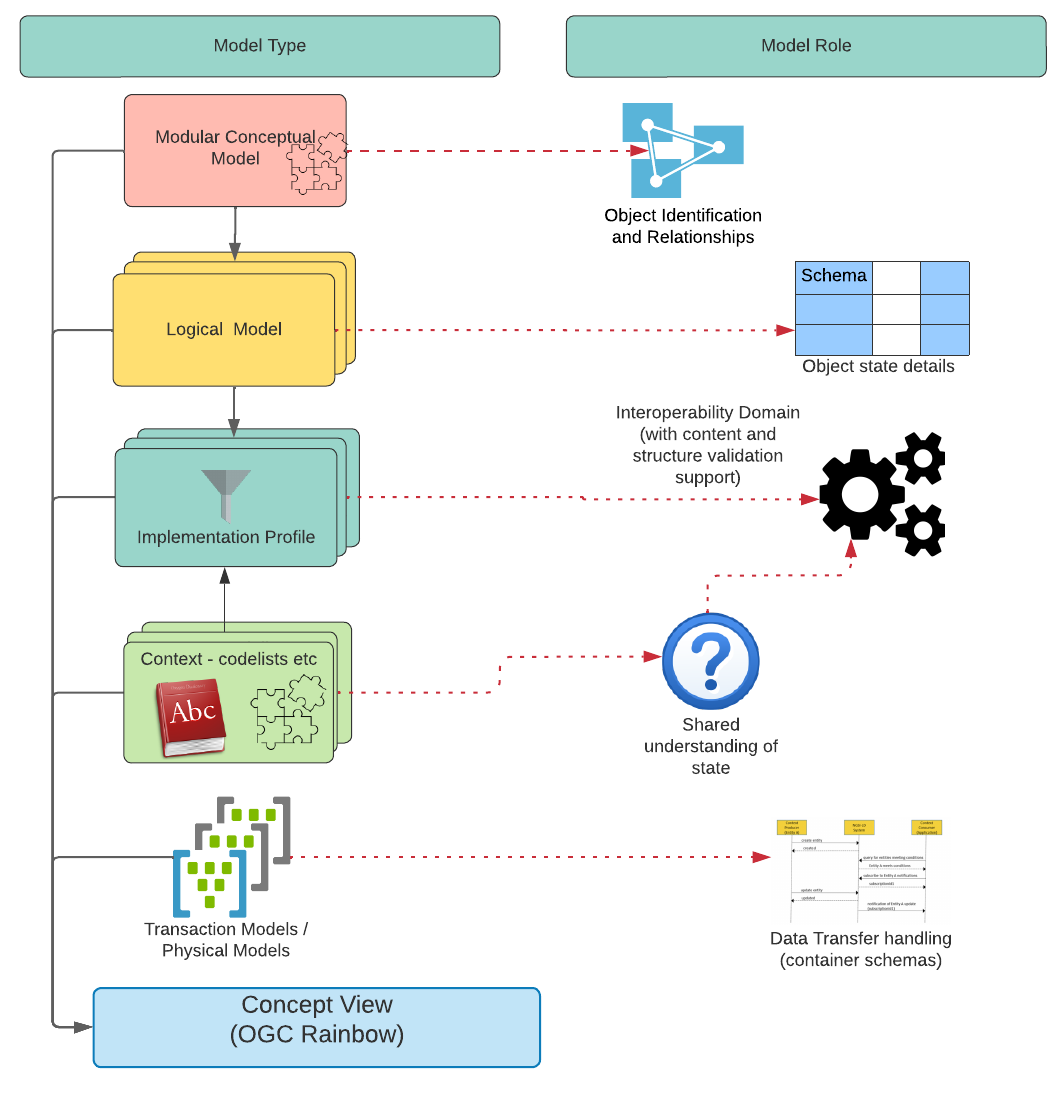
Relationships between models
The following graphic shows the relationship of the different model levels and the role that the respective model plays in the operational context.